
Building DevDocAI - An AI That Writes Your Docs | Part 1: Foundation
Part 1: Foundation

Series: Building DevDocAI - A Production Multi-Agent LangGraph System Part 1 - Foundation: Backend, Auth, DB, GitHub OAuth, MCP Server
The Problem
Every engineering team has the same dirty secret: the docs are lying.
Not intentionally. Code moves fast, documentation doesn't. A new dev joins → spends 2 weeks reading outdated wikis → still has to disturb 3 senior engineers just to understand one service.
I got tired of it. So I'm building DevDocAI.
What is DevDocAI?
DevDocAI is a production-grade multi-agent LangGraph system that:
Connects to your GitHub repo
Reads your codebase at the AST level (not just text — actual code structure)
Auto-generates structured documentation per module/function
Updates docs automatically every time a PR gets merged
Has an onboarding chatbot — new devs can ask "what does this function do?" and get real answers from live code
The key word is agent — not just a RAG chatbot. This system understands your code.
The Full Agent Pipeline (What I'm Building)
START
↓
codebase_parser ← AST-level parsing of GitHub repo
↓
doc_generator ← LLM generates structured docs per module/function
↓
brave_researcher ← enriches with external context (libraries, best practices)
↓
HITL checkpoint ← YOU review generated docs before publish
↓
doc_publisher ← saves to DB + updates vector store
↓
pr_watcher ← GitHub webhook re-triggers on every PR merge
↓
END
Parallel → onboarding_chatbot ← RAG over vector store for new devs
The HITL (Human-in-the-Loop) part is what makes this real. The LangGraph pipeline literally pauses, waits for a dev to approve via the frontend, then resumes. Not just vibes — actual workflow.
Tech Stack
| Layer | Tech | Why |
|---|---|---|
| Agent Framework | LangGraph | Multi-agent, HITL, checkpointing |
| Backend | FastAPI + Python | Async, fast, clean |
| Frontend | Next.js + Tailwind | (coming Phase 6) |
| LLM | Groq llama-3.3-70b | Blazing fast inference |
| Embeddings | Cohere | Best-in-class embeddings |
| Vector DB | Qdrant | Production-grade, pure Python client |
| Web Search | Brave Search API | Dev-focused, privacy-first |
| Observability | LangSmith | Agent traces, debugging |
| Tool Protocol | MCP | Modern tool standard |
| Auth | JWT + GitHub OAuth | Secure, industry standard |
| Cache | Redis (Upstash) | (coming Phase 5) |
| Storage | AWS S3 | Doc storage |
| DB | PostgreSQL | Neon (prod), Docker (dev) |
| Deployment | ECR + ECS Fargate | (coming Phase 7) |
| CI/CD | GitHub Actions | (coming Phase 7) |
Architecture — The Pattern I Follow
Every layer has one job. No exceptions.
Route → HTTP only (request/response)
↓
Service → Business logic
↓
Repository → DB queries only
↓
Database
This is what separates a demo from something real. When 5 engineers touch the same codebase, this pattern saves you.
Folder Structure
backend/
├── auth/
│ ├── jwt.py ← token create/verify
│ ├── github_oauth.py ← GitHub OAuth flow
│ └── routes.py ← HTTP layer only
├── db/
│ ├── database.py ← async PostgreSQL
│ └── models.py ← SQLAlchemy models
├── repositories/
│ └── user_repository.py ← all DB queries here
├── schemas/
│ └── auth_schemas.py ← Pydantic request/response
├── services/
│ └── auth_service.py ← business logic
├── utils/
│ ├── helper_auth.py ← bcrypt helpers
│ └── encryption.py ← Fernet token encryption
├── mcp/
│ └── github_server.py ← GitHub tools for agents
├── agents/ ← Phase 4
├── graph/ ← Phase 3
├── webhooks/ ← Phase 5
└── main.py
Database Design
4 tables, all connected:
User
└── Repository
├── Document ← generated docs (PENDING → APPROVED → PUBLISHED)
└── PipelineRun ← LangGraph execution tracking
A few production decisions I made:
UUIDs over integer IDs — no sequential ID enumeration attacks.
Fernet encryption for GitHub tokens — never store access tokens in plaintext. Ever.
# utils/encryption.py
from cryptography.fernet import Fernet
_fernet = Fernet(settings.ENCRYPTION_KEY.encode())
def encrypt(value: str) -> str:
return _fernet.encrypt(value.encode()).decode()
def decrypt(value: str) -> str:
return _fernet.decrypt(value.encode()).decode()
Indexes on Document table — repo_id, file_path, status are all indexed because these will be queried constantly at scale.
DocStatus enum for proper state machine:
PENDING → APPROVED → PUBLISHED
PENDING → REJECTED
GitHub OAuth Flow
Frontend → GET /auth/github → GitHub redirect URL
↓
User authorizes on GitHub
↓
GitHub → POST /auth/github/callback?code=xxx
↓
Code → access_token exchange
↓
Token encrypted → stored in DB
↓
JWT returned → Frontend
Clean separation — routes.py only handles HTTP, auth_service.py has all the logic, user_repository.py handles all DB queries.
MCP Server — GitHub Tools for Agents
Built 6 tools that LangGraph agents will use:
GITHUB_TOOLS = [
get_repo_contents, # list files/folders
get_file_content, # read a file's source code
list_branches, # all branches
get_pr_details, # PR changed files (for pr_watcher)
get_repo_info, # repo metadata
list_python_files, # recursively find all .py files
]
These are @tool decorated LangChain tools — agents can call them directly in the pipeline.
Dev vs Prod Database Setup
One thing I'm proud of: proper environment parity from day one.
# database.py
connect_args = {"ssl": "require"} if settings.DATABASE_SSL else {}
engine = create_async_engine(
settings.DATABASE_URL,
connect_args=connect_args,
...
)
Dev → Docker postgres:16 locally → DATABASE_SSL=False
Prod → Neon PostgreSQL → DATABASE_SSL=True
Same code, different config. No hacks.
What It Looks Like Running
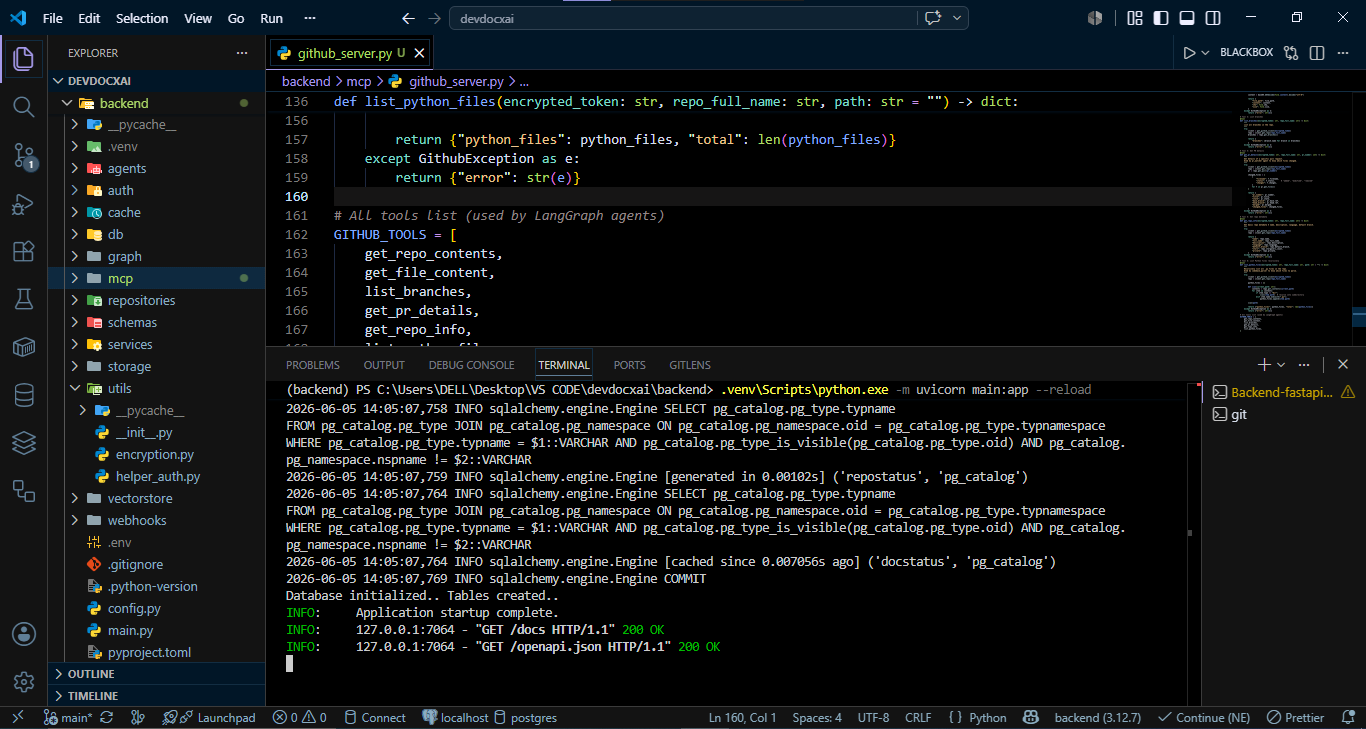
After uvicorn main:app --reload, the DB initializes automatically:
✅ CREATE TYPE repostatus AS ENUM (...)
✅ CREATE TYPE docstatus AS ENUM (...)
✅ CREATE TABLE users (...)
✅ CREATE TABLE repositories (...)
✅ CREATE TABLE documents (...) ← with indexes
✅ CREATE TABLE pipeline_runs (...)
✅ Database initialized. Tables created.
✅ Application startup complete.
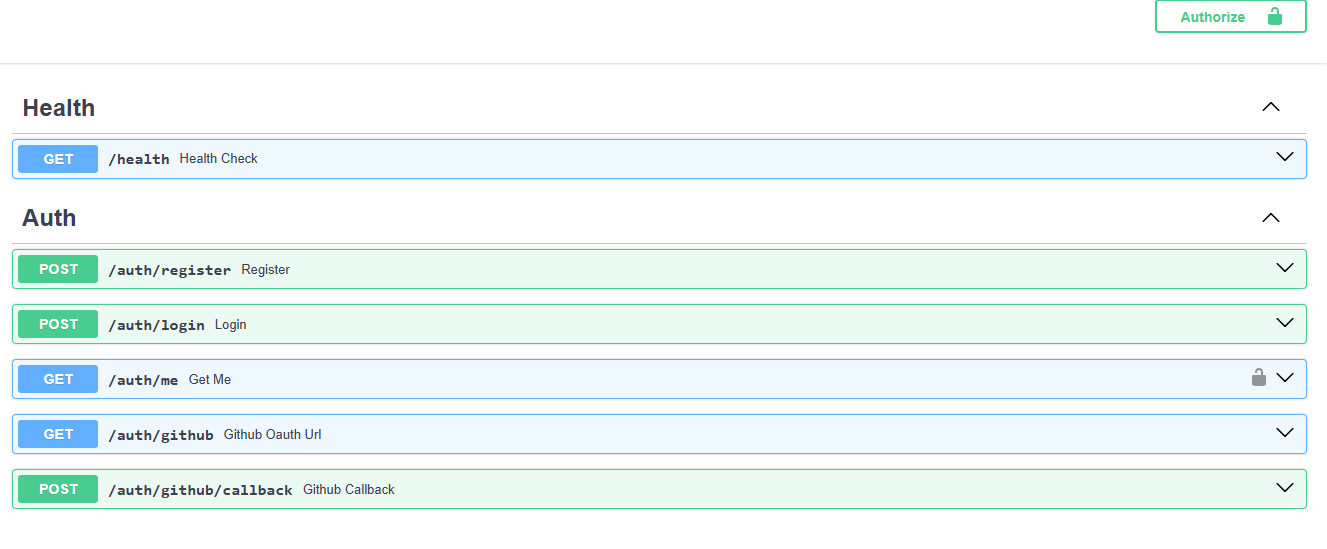
And Swagger UI at /docs shows all endpoints live:
Key Learnings from Phase 1 + 2
1. Foundation takes time — and that's fine. Two phases before writing a single agent. Every senior engineer says the same thing: boring infrastructure is what separates a demo from a product.
2. Pydantic v2 — use model_config, not class Config.
# Wrong (Pydantic v1 style)
class Config:
from_attributes = True
# Correct (Pydantic v2)
model_config = ConfigDict(from_attributes=True)
3. Never store tokens in plaintext. Fernet encryption, always. Takes 10 minutes to set up, protects your users forever.
4. Repository layer is not optional. The moment you have DB queries in your service layer, you've lost. Create a repositories/ folder early, thank yourself later.
What's Next — Part 2
Phase 3 is LangGraph Core:
graph/state.py— the State schema that flows through all agentsgraph/pipeline.py— connecting all agents into one graphgraph/hitl.py— the pause/resume HITL checkpoint logic
This is where it gets exciting. The graph will actually start running.
Follow the series to catch Part 2 when it drops! 🚀
GitHub
Building in public. Part 2 dropping soon.
Tags: python ai langchain productivity beginners